
یادگیری تقویتی یکی از جدیدترین و مهمترین رویکردها در دنیای هوش مصنوعی به شمار میآید که به طور قابل توجهی به بهبود کارایی سیستمهای یادگیری ماشین کمک میکند. این روش به ویژه در مدلهای زبان بزرگ مانند QwQ-32B علیبابا کلاد و DeepSeek-R1 تأثیرات مثبتی را در راستای افزایش دقت و کارایی آنها به ثبت رسانده است. نتایج نشان میدهد که یادگیری تقویتی به مدلها این امکان را میدهد که از تجربیات گذشته خود درس بگیرند و به تدریج بهبود یابند. با بکارگیری این تکنیک، علیبابا موفق به ارائه مدلی شده که توانایی مطلوبی را در مقایسه با دیگر مدلهای بزرگ زبان، حتی با تعداد پارامترهای کمتر، به ارمغان میآورد. در این مقاله، به بررسی جزئیات بیشتر درباره یادگیری تقویتی و نقش آن در پیشرفتهای یادگیری ماشین و هوش مصنوعی خواهیم پرداخت.
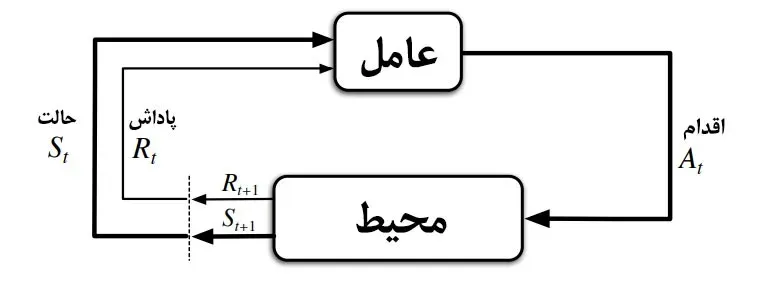
روشهای تقویتی در یادگیری ماشین به عنوان رویکردهای خلاقانه برای آموزش سیستمهای هوش مصنوعی مطرح شدهاند، که در آنها عاملهای هوشمند از طریق تعامل با محیط خود و دریافت پاداش به فراگیری میپردازند. این نوع یادگیری به خصوص در مدلهای پیشرفته مانند QwQ-32B و سایر سیستمهای هوش مصنوعی گسترش یافته است. در واقع، با پیادهسازی مدلهای زبان بزرگ، این رویکردها میتوانند به اهداف مشخصی در زمینه استدلال و حل مسائل پیچیده دست یابند. رویکرد یادگیری تقویتی به سیستمها این امکان را میدهد که به صورت تدریجی و با استفاده از شبیهسازی تجربیات واقعی، تصمیمات بهتری اتخاذ کنند. از این رو، آینده هوش مصنوعی بیشتر به استفاده از این نوع یادگیری در مدلها و برنامههای کاربردی وابسته است.
یادگیری تقویتی و نقش آن در بهبود مدلهای زبان بزرگ
یادگیری تقویتی (Reinforcement Learning یا RL) به عنوان یکی از رویکردهای پیشرفته در حوزه هوش مصنوعی، توانسته است تحولات چشمگیری در عملکرد سیستمهای هوشمند ایجاد کند. این تکنیک بهویژه در مدلهای زبان بزرگ، مانند QwQ-32B علیبابا، اثر مثبتی داشته است. با استفاده از یادگیری تقویتی، مدلها میتوانند با استفاده از تجربههای گذشته خود، به نحوی شایستهتر و بهینهتر عمل کنند. این نوع آموزش به مدل کمک میکند تا با محیط خود تعامل کرده و از طریق آزمون و خطا، راهحلهای بهتری را برای انجام وظایف خود پیدا کند.
مدل QwQ-32B با به کارگیری ۳۲ میلیارد پارامتر و استفاده از روش یادگیری تقویتی، توانسته است به عملکردی قابل رقابت با مدلهای بزرگتری همچون DeepSeek-R1 دست یابد که دارای ۶۷۱ میلیارد پارامتر هستند. این پیشرفت نشان دهنده این است که یادگیری تقویتی میتواند به بهبود استدلال و مهارتهای کدنویسی مدلهای هوش مصنوعی کمک کند. به این ترتیب، علیبابا با بهرهگیری از RL، مسیر جدیدی را در توسعه مدلهای زبان بزرگ هموار کرده است.
سوالات متداول
یادگیری تقویتی چیست و چه تأثیری بر هوش مصنوعی دارد؟
یادگیری تقویتی (Reinforcement Learning) به عنوان یکی از روشهای آموزش سیستمهای هوش مصنوعی، به توسعهدهندگان این امکان را میدهد که با استفاده از بازخورد محیطی، مدلها را آموزش دهند. این روش، با ایجاد محیطی برای آزمایش و خطا، قدرت استدلال عمیقتری را به هوش مصنوعی میبخشد و باعث بهبود عملکرد مدلهای پایه مثل QwQ-32B علیبابا میشود.
مدلهای بزرگ زبان مانند QwQ-32B چگونه از یادگیری تقویتی استفاده میکنند؟
مدلهای بزرگ زبان همچون QwQ-32B از یادگیری تقویتی به منظور بهبود مهارتهای استدلال و تفسیر محیط استفاده میکنند. با بهرهگیری از RL، این مدلها میتوانند به بازخوردها واکنش نشان دهند و با ترکیب اطلاعات جدید با دانش قبلی، تصمیمات بهتری اتخاذ نمایند.
مقایسه یادگیری تقویتی با دیگر شیوههای یادگیری ماشین در چیست؟
یادگیری تقویتی بر اساس پاداش و مجازات عمل میکند و به مدلها اجازه میدهد که از تجربیات خود یاد بگیرند. این در مقایسه با یادگیری نظارتشده و بدون نظارت، که عمدتاً به دادههای آموزشی وابسته هستند، ویژگی منحصربهفردی است که به پیشرفت هوش مصنوعی در زمینههایی مانند استدلال و تصمیمگیری کمک میکند.
چگونه علیبابا کلاد از یادگیری تقویتی برای بهبود مدلهای خود استفاده کرده است؟
علیبابا کلاد با استفاده از یادگیری تقویتی مداوم، موفق به بهبود عملکرد مدل QwQ-32B در زمینههای استدلال ریاضی و مهارتهای کدنویسی شده است. این سیستم، با بهرهگیری از ۳۲ میلیارد پارامتر، عملکردی قابل مقایسه با مدلهای بزرگ دیگر همچون DeepSeek-R1 را فراهم کرده است.
آیا یادگیری تقویتی تنها برای هوش مصنوعی مفید است یا در سایر حوزههای یادگیری ماشین نیز کاربرد دارد؟
یادگیری تقویتی نه تنها در هوش مصنوعی، بلکه در سایر حوزههای یادگیری ماشین نیز کاربرد دارد. این روش به مدلها این امکان را میدهد که با درک عمیقتر از محیط، تصمیمات بهتری بگیرند و در نتیجه به کارایی بالاتری دست یابند.
چرا RL در توسعه نسل بعدی هوش مصنوعی مهم است؟
یادگیری تقویتی (RL) به توسعه دهندگان این امکان را میدهد که با ارتقای هوش مصنوعی در راستای تطبیق با محیط و یادگیری از تجربیات، به سمت هوش مصنوعی عمومی (AGI) گام بردارند. این فرایند نه تنها باعث بهبود قابلیتهای مدلها میشود، بلکه به پیشرفتهای چشمگیری در فرآیندهای یادگیری ماشین منجر میشود.
مدل DeepSeek چگونه به یادگیری تقویتی مرتبط است؟
مدل DeepSeek با استفاده از یادگیری تقویتی به عنوان یک رویکرد اساسی، توانسته است نتایجی مشابه با مدلهای بزرگ زبان آمریکایی ارائه دهد. RL به عنوان ابزاری موثر در این مدل، موجب میشود که بتواند بدون نیاز به سختافزار پیشرفته، کارایی بالایی در پردازش دادهها داشته باشد.
چگونه میتوان از یادگیری تقویتی در پروژههای خود بهرهبرداری کرد؟
برای استفاده از یادگیری تقویتی در پروژههای خود، ابتدا باید محیطی مناسب برای آزمایش و خطا ایجاد کرد. سپس با تعریف پاداشها و مجازاتها، مدل را آموزش داده و از بازخوردهای حاصل برای بهبود عملکرد آن استفاده کنید. این فرایند میتواند به بهینهسازی سیستمهای هوش مصنوعی کمک کند.
| ویژگی | مدل QwQ-32B | مدل DeepSeek-R1 |
|---|---|---|
| پارامترها | ۳۲ میلیارد | ۶۷۱ میلیارد |
| عملکرد | قابل مقایسه با مدلهای بزرگ هوش مصنوعی | قابل مقایسه با QwQ-32B و دیگر مدلها |
| روش یادگیری | یادگیری تقویتی | یادگیری تقویتی |
| توسعهدهنده | علیبابا کلاد | DeepSeek چین |
| تواناییهای کلیدی | استدلال ریاضی، مهارت کدنویسی | مقابله با مدلهای آمریکایی بدون سختافزار قوی |
خلاصه
یادگیری تقویتی یک روش مهم و مؤثر در بهبود عملکرد هوش مصنوعی است. این تکنیک، قابلیتهای پیشرفتهای را برای مدلها فراهم میکند که به آنها اجازه میدهد در محیط خود به طور فعال عمل کنند و از طریق تجربیات، مهارتهای خود را تقویت کنند. به نظر میرسد که علیبابا با استفاده از یادگیری تقویتی در مدل QwQ-32B خود توانسته است عملکرد قابل مقایسهای با مدلهای بزرگتر و پیچیدهتر ارائه دهد. این موفقیت نشاندهنده قدرت یادگیری تقویتی در توسعه نسلهای بعدی هوش مصنوعی است.